
“微信扫一扫”进入"可可试卷"微信小程序刷题
中级经济师《基础知识》题库(1402题)
第821题
关于大数据多样性的说法正确的有( )。
A.大数据包括半结构化数据
B.大数据必须是结构规则、完整的数据
C.大数据包括结构化数据
D.大数据包括非结构化数据
E.地理位置是大数据的一种类型
参考答案:ACDE
解析:
本题考查大数据。
大数据类型繁多,包括网络日志、音频、视频、图片、地理位置等各种结构化、半结构化和非结构化的数据。
非结构化数据是指数据结构不规则或不完整,没有预定义的数据。
半结构化数据是介于完全结构化数据和完全非结构化数据之间的数据,具有一定的结构性。所以B错误。
故本题正确答案为ACDE。
【思路点拨】从举例上来理解并区分结构化、半结构化和非结构化的数据。
结构化数据,简单说就是数据库。如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。
非结构化数据,包括所有格式的办公文档、文本、图片、报表、图像、音频、视频。
半结构化数据,如员工简历,有的简历只有教育情况,有的简历包括教育、婚姻、户籍、出入境情况等很多信息。
第822题
下列关于数据挖掘的表述正确的有( )。
A.数据挖掘是指从大量的、完全的、有噪声的、清晰的、随机的实际应用数据中,提取隐藏在其中但又有潜在价值的信息和知识的过程
B.数据挖掘以解决实际问题为出发点
C.数据挖掘常用的方法可分为监督学习、无监督学习和半监督学习
D.主成分分析法属于聚类方法
E.无监督学习中有两大类典型任务:聚类和降维
参考答案:BCE
解析:
本题考查数据挖掘。
数据挖掘是指从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐藏在其中但又有潜在价值的信息和知识的过程,A项错误;
聚类方法:基于划分的方法[例如k均值聚类算法]、基于分层的方法、基于密度的方法、基于网格的方法和基于模型的方法;
降维方法:主成分分析法、因子分析法,D项错误。
故本题正确答案为BCE。
第823题
下列属于无监督学习的是( )。
A.决策树
B.线性回归
C.因子分析
D.随机森林
参考答案:C
解析:
本题考查数据挖掘。
无监督学习中有两大类典型任务:聚类和降维。常用的聚类方法包括基于划分的方法(例如,k均值聚类算法)、基于分层的方法、基于密度的方法、基于网格的方法和基于模型的方法。常用的降维方法包括主成分分析法、因子分析法等。ABD不符合题意。
本题答案为C。
第824题
把一组数据按照差异性和相似性分为几个类别,使得同类的数据相似性尽量大,不同类的数据相似性尽可能小,跨类的数据关联性尽可能低的是( )。
A.分类
B.回归
C.聚类分析
D.降维
参考答案:C
解析:
本题考查数据挖掘。
聚类就是把一组数据按照差异性和相似性分为几个类别,使得同类的数据相似性尽量大,不同类的数据相似性尽可能小,跨类的数据关联性尽可能低。C选项正确,ABD选项与题意无关。C正确。
【思路点拨】注意区分这几个选项,避免混淆。
分类:通过特征变量确定观测单位所属的类别,因变量是分类变量。
回归:通过特征变量确定观测单位因变量的取值,因变量是定量变量。
降维:也称为特征提取,指在不损失过多信息的前提下将N个相关的特征降为k个不相关的特征(其中 k<N) 使其具有更好的解释性。
第825题
下列不属于监督学习中的分类方法的是( )。
A.逻辑斯特回归
B.决策树
C.随机森林
D.基于密度的方法
参考答案:D
解析:
本题考查数据挖掘。
监督学习中常用的分类方法有逻辑斯特回归、决策树、随机森林和支持向量机等。ABC选项正确。D不符合题意。
本题为反选题,故本题选择D选项。
【思路点拨】区分监督学习的分类方法和无监督学习的聚类方法,避免混淆。
常用的分类方法有逻辑斯特回归、决策树、随机森林和支持向量机等
常用的聚类方法包括基于划分的方法(例如k均值聚类算法)、基于分层的方法、基于密度的方法、基于网格的方法和基于模型的方法。
第826题
集中趋势的测度,主要包括( )。
A.方差和标准差
B.众数和离散系数
C.标准分数
D.中位数和众数
参考答案:D
解析:
考查集中趋势的测度。
集中趋势的测度,主要包括:均值、中位数、众数。
离散程度的测度包括方差、标准差、离散系数。
分布形态的测度包括偏态系数、标准分数。
ABC选项错误。
故此题正确答案为D。
【思路点拨】
集中趋势是指一组数据向某一中心值靠拢的程度,集中趋势的测度也就是寻找数据一般水平的代表值或中心值。
均值也就是平均数,就是数据组中所有数值的总和除以该组数值的个数。均值是集中趋势中最主要的测度值。
中位数把一组数据按从小到大或从大到小的顺序进行排列,位置居中的数值叫做中位数 。中位数将数据分为两部分,其中一半的数据小于中位数,另一半数据大于中位数。
众数是指一组数据中出现次数(频数)最多的变量值。
第827题
下列指标中,用于描述定量数据集中趋势,并且易受极端值影响的是( )。
A.算术平均数
B.中位数
C.众数
D.极差
参考答案:A
解析:
考查集中趋势的测度。
描述定量数据集中趋势的指标有均值(即算术平均数)和中位数,均值易受极端值的影响,中位数不受极端值的影响。A选项正确,B选项错误。
众数不适用于描述定量数据的集中趋势。C选项错误。
极差是指一组测量值内最大值与最小值之差。D选项错误。
故此题正确答案为A。
【思路点拨】
均值、中位数和众数的比较

第828题
( )的测度值是对数据一般水平的一个概括性度量,它对一组数据的代表程度,取决于该组数据的( )。
A.集中趋势;离散程度
B.离散程度;集中程度
C.极差;组距
D.方差;算术平均数
参考答案:A
解析:
考查集中趋势的测度。
离散程度反映的是数据之间的差异程度。集中趋势的测度值是对数据水平的一个概括性的度量,它对一组数据的代表程度,取决于该组数据的离散水平。数据的离散程度越大,集中趋势的测度值对该组数据的代表性就越差,离散程度越小,其代表性就越好。符合题干要求的是A项。
故此题正确答案为A。
【思路点拨】在描述统计中,可以通过统计量描述数据的分布特征。对于数据分布特征的测度主要分为三个方面:
一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;
二是分布的离散程度,反映各数据之间的差异程度,也能反映中心值对数据的代表程度;
三是分布的偏态,反映数据分布的不对称性。对于两个定量变量之间的相关分析,经常采用的描述方法是散点图和相关系数统计量。
第829题
某连锁超市6个分店的职工人数从小到大排序后为57人、58人、58人、60人、63人、70人其均值、中位数分别为( )。
A.59、58
B.61、58
C.61、59
D.61、70
参考答案:C
解析:
考查集中趋势的测度。
均值也叫作平均数,就是数据中所有数值的总和除以该组数值的个数。
均值=(57+58+58+60+63+70)/6=61
中位数就是把一组数据按从小到大的顺序进行排列,位置居中的数值叫做中位数。
中位数=(58+60)/2=59
故此题正确答案为C。
【思路点拨】根据未分组数据计算中位数时,要先对数据进行排序,然后确定中位数的位置,其公式为:
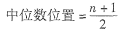
式中,n为数据的个数。最后确定中位数的具体数值。中位数将数据分成两部分,其中一半数据小于中位数,另一半数据大于中位数。设一组数据为X1,X2 ,…,Xn,按从小到大顺序为X(1),X(2) ,…,X(n)则中位数为:

第830题
一家连锁酒店8个分店某月的营业额(单位:万元)为:60、60、70、80、80、70、70、65,那么这8个分店月营业额的中位数为( )。
A.60
B.65
C.70
D.80
参考答案:C
解析:
考查集中趋势的测度。
中位数就是把一组数据按从小到大的顺序进行排列,位置居中的数值叫做中位数。
首先要将数据从小到大排列的结构时60,60,65,70,70,70,80,80,则中位数第4个数和第5个数的均值,即(70+70)/2=70
故此题正确答案为C。
【思路点拨】
根据未分组数据计算中位数时,要先对数据进行排序,然后确定中位数的位置,n为数据的个数,其公式为:
(1)n为奇数:中位数位置是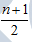 ,该位置所对应的数值就是中位数数值。
,该位置所对应的数值就是中位数数值。
(2)n为偶数:中位数位置是介于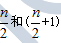 之间,中位数就是这两个位置对应的数据的均值。
之间,中位数就是这两个位置对应的数据的均值。
第831题
某小学六年级8个班的学生人数由少到多依次为34人、34人、34人、34人、36人、36人、37人、37人,其中位数为( )人。
A.34
B.35
C.36
D.37
参考答案:B
解析:
考查集中趋势的测度。
把一组数据按从小到大的顺序进行排列,位置居中的数据叫做中位数。
题干中的数据已经为从小到大依次排序,由于n为偶数,故中位数= (34 +36)/2 =35 。
故此题正确答案为B。
第832题
2019年某市下辖7个县的棉花种植面积按规模由小到大依次为800公顷、900公顷、1100公顷、1400公顷、1500公顷、3000公顷,3200公顷,这七个县棉花种植面积的中位数是( )公顷。
A.1450
B.1250
C.1100
D.1400
参考答案:D
解析:
考查集中趋势的测度。
把一组数据按从小到大的顺序进行排列,位置居中的数据叫做中位数。
题干中的数据已经为从小到大依次排序,由于n等于奇数,所以中位数位置是(7+1)/2=4,即第4个数为中位数。
故此题正确答案为D。
第833题
一组数据中出现频数最多的数值是( )。
A.众数
B.标准差
C.均值
D.中位数
参考答案:A
解析:
本题考查众数。
众数是一组数据中出现频数最多的数值。A说法符合题意。BCD均与本题考查内容无关。
故此题正确答案为A。
【思路点拨】标准差是方差的平方根。均值一般指平均数。把一组数据按从小到大或从大到小的顺序进行排列,位置居中的数值叫做中位数 。
第834题
某企业在全国设有10个分公司,2015年底这些分公司的员工人数(单位.人)分别为:15 17 18 19 19 20 21 25 25 25 这组数据的众数是( )人。
A.15
B.19
C.21
D.25
参考答案:D
解析:
考查集中趋势的测度。
众数是一组数据中出现频数最多的那个数值。
在题干中的数据中,25出现的次数最多,所以众数是25.
故此题正确答案为D。
第835题
2021年某地级市下辖的8个县区的耕地面积(单位:千公顷)分别为:12、14、20、22、28、28、28、33,这组数据的中位数和众数分别是( )千公顷。
A.27,12
B.33,12
C.23,28
D.25,28
参考答案:D
解析:
本题考查众数。
要计算中位数——先排序,再找中间位置。
数据的个数n=8,为偶数,(8+1) /2==4.5,
所以,中位数取第4个和第5个位置上数值的平均数,中位数=(22+28)/2=25。
28出现了3次,出现的次数最多,所以众数为28。
本题答案为D。
【思路点拨】根据未分组数据计算中位数时,要先对数据进行排序,然后确定中位数的位置,其公式为:
式中,n为数据的个数。最后确定中位数的具体数值。设一组数据为X1,X2 ,…,Xn,按从小到大顺序为X(1),X(2) ,…,X(n)则中位数为:
第836题
下列统计量中,适用于顺序数据的有( )。
A.中位数
B.方差
C.标准差
D.众数
E.均值
参考答案:AD
解析:
考查均值、中位数、众数的比较及适用范围
众数适用于分类数据和顺序数据;中位数适用于顺序数据和数值型数据;均值、方差、标准差等只适用于数值型数据。
本题答案为AD。
【思路点拨】均值、中位数和众数的比较及各自的适用范围:
①均值适于定量变量。优点是能够充分利用数据的全部信息,均值大小受每个观测值的影响,比较稳定;缺点是易受极端值的影响,如果观栅值中有明显的极端值,则均值的代表性较差。
②中位数不适于分类变量,适于顺序变量和定量变量,特别是分布不对称的数据。优点是不受极端值的影响;缺点是没有充分利用数据的全部信息,稳定性差于均值,优于众数。
③众数不适用于定量变量,主要适用于分类和顺序变量。优点是不受极端值的影响,尤其是分布明显呈偏态时,众数的代表性更好;缺点是没有充分利用数据的全部信息,缺乏稳定性,而且可能不唯一。
第837题
下列有关均值(即平均数)、中位数和众数的说法中,正确的有( )。
A.均值是集中趋势最主要的测度值,主要适用于数值型数据,不适用于分类数据和顺序数据
B.中位数是一个位置代表值,主要适用于顺序数据和数值型数据,但不适用于分类数据
C.众数适用于描述分类数据和顺序数据,不适用于描述定量数据的集中位置
D.在定量数据中,一组数据的众数是唯一的
E.众数是指一组数据中出现次数(频数)最多的变量值,众数比较稳定
参考答案:ABC
解析:
考查均值、中位数和众数的比较及适用范围。
均值也叫作平均数,是数据组中所有数值的总和除以该组数值的个数。均值是集中趋势最主要的测度值,主要适用于数值型数据,不适用于分类数据和顺序数据。选项A正确。
把一组数据按从小到大或从大到小的顺序进行排列,位置居中的数值叫作中位数。中位数是一个位置代表值,主要适用于顺序数据和数值型数据,但不适用于分类数据。选项B正确。
众数是指一组数据中出现次数(频数)最多的变量值。众数的缺点是没有充分利用数据的全部信息,缺乏稳定性,而且可能不唯一。选项E错误。
众数适用于描述分类数据和顺序数据的集中趋势,不适用于描述定量数据的集中位置。在定量数据中,可能出现多众数或无众数的情况。选项C正确,选项D错误。
本题答案为ABC。
第838题
下列统计量中,用于测度数据分布集中趋势的有( )
A.中位数
B.众数
C.平均数
D.标准分数
E.偏态系数
参考答案:ABC
解析:
考查集中趋势的测度。
集中趋势的测度包括平均数、中位数、众数),ABC正确。DE属于分布形态的测度。
故本题正确答案为ABC。
【思路点拨】根据题干所问什么测度数据去进行分辨:
集中趋势的测度(均值也就是平均数、中位数、众数)
离散程度的测度(方差、标准差、离散系数)
分布形态的测度(偏态系数、标准分数)
变量间的相关分析(散点图及相关系数)
第839题
下列数据特征的测度值中,易受极端值影响的是( )。
A.中位数
B.众数
C.算术平均数
D.位置平均数
参考答案:C
解析:
考查集中趋势的测度。
算术平均数易受极端值的影响。极端值的出现,会使平均数的真实性受到干扰。
中位数和众数不受极端值的影响。位置平均数:是指按数据的大小顺序或出现频数的多少,确定的集中趋势的代表值,主要有众数、中位数等。ABD选项错误。
故此题正确答案为C。
第840题
下列关于标准差的表述错误的是( )。
A.能够度量数值与均值的平均距离
B.用来测量数据的离散程度
C.与原始数值具有相同的计量单位
D.用来测量数据的集中趋势
参考答案:D
解析:
考查离散程度的测度。
标准差用来测度数据的离散程度,是方差的平方根,能度量数值与均值的平均距离,还与原始数值具有相同的计量单位。
ABC选项正确,D选项说法错误,测量集中趋势的指标是均值,众数,中位数。
故此题正确答案为D。